Implementing JavaScript in Rust
I was excited about Rust since I first heard about it; A language, with the flexibility of "modern" languages, but with the performance of C, without the complexity of C++!
So I searched for a simple project to get started with Rust. My first idea was to write a small web server. HTTP is a very simple protocol to implement, I only have to implement one side of the protocol, because the web browser is already there, and since I am a web developer, and I know enough about the domain problems, so I can concentrate on the Rust part.
Good idea right? I began learning Rust by reading the Rust Book, and turns out: the authors had the very same idea (link). I got bored pretty quickly and realized I needed a more exciting challenge to keep engaged.
I always was interested in frameworks, API design, and programming languages. So I thought it would be fun to implement an interpreter. The plan is to write a lexer and parser first, and later create a compiler, using LLVM.
The whole source code for the project is available here: https://github.com/fscherf/JavaScript.rs
First Milestone: Writing a Lexer
This will be a series of blog posts, starting with this one, implementing the lexer. The challenge will be to lex this snippet of JavaScript code:
function add(a, a) {
return a + b;
}
const a = 5;
const b = 6;
console.log('a + b =', add(a, b));
Why JavaScript?
My first idea was to create my very own, fantasy-language, but I had no idea for a new but usable syntax, or a fun quirk, developers would have to work around, while programming in my language. I like the Python syntax and the syntax of C-style programming languages. Python is a bit harder to tokenize and lex, because of its use of significant whitespace.
JavaScript ticked all boxes. It is a C-style language, so it should be pretty easy to parse, and it is a pretty quirky language, for example with its weird truth table. So I thought: should be fun to implement! A bonus of implementing a well established programming language: you can find lots and lots of test code on the internet, and there is a reference implementation, which you can check your implementation against.
 Source: https://algassert.com/visualization/2014/03/27/Better-JS-Equality-Table.html
Source: https://algassert.com/visualization/2014/03/27/Better-JS-Equality-Table.html
Getting Started with Rust
First of all, obviously, I needed Rust on my system. I use Linux Mint, so there are multiple ways to install it. Linux Mint has a Rust package, but it was not the most recent version of Rust, which should be no problem for my intended purpose to be honest, but I did not want to miss out on the latest features and tools, so I chose https://sh.rustup.rs.
This way of installation was a bit scary. Piping the output of curl directly into a shell sounds dangerous to me but since all cool kids are doing it, I wanted to be cool as-well. Also: I am using pyenv for Python development for years now, which has a similar approach, but uses git instead of curl.
The installation process went absolutely smoothly, and I like Rust's "batteries-included" approach: In Python, you have multiple ways to handle and install packages and multiple ways for entry-points and command-line tools. In Rust you have cargo, which does compilation, package-management, and feels like GNU Make, a tool I like a lot.
I use VS Code, so I installed the recommended extension rust-analyzer.
rust-analyzer is very helpful, but in its default configuration, it adds a lot of visual noise to the code, which drove me crazy. Most of the time, I have a clear mental model of how the code looks, and where to change it. Having a tool, that adds lines or words to the code, which are not really there, confused me multiple times.
I ended up disabling pretty much all visual features, besides the basic syntax highlighting, using this config snippet:
// ~/.config/Code/User/settings.json
[...]
"rust-analyzer.inlayHints.chainingHints.enable": false,
"rust-analyzer.completion.autoimport.enable": false,
"rust-analyzer.hover.actions.references.enable": true,
"rust-analyzer.inlayHints.parameterHints.enable": false,
"rust-analyzer.inlayHints.typeHints.enable": false,
"rust-analyzer.completion.postfix.enable": false,
"rust-analyzer.completion.autoself.enable": false,
"rust-analyzer.inlayHints.closingBraceHints.enable": false,
"rust-analyzer.lens.implementations.enable": false,
"rust-analyzer.lens.enable": false,
"rust-analyzer.debug.openDebugPane": true,
"editor.semanticTokenColorCustomizations": {
"enabled": true,
"rules": {
"*.mutable": {
"underline": false
}
}
},
[...]
After that, I was good to go!
First Steps
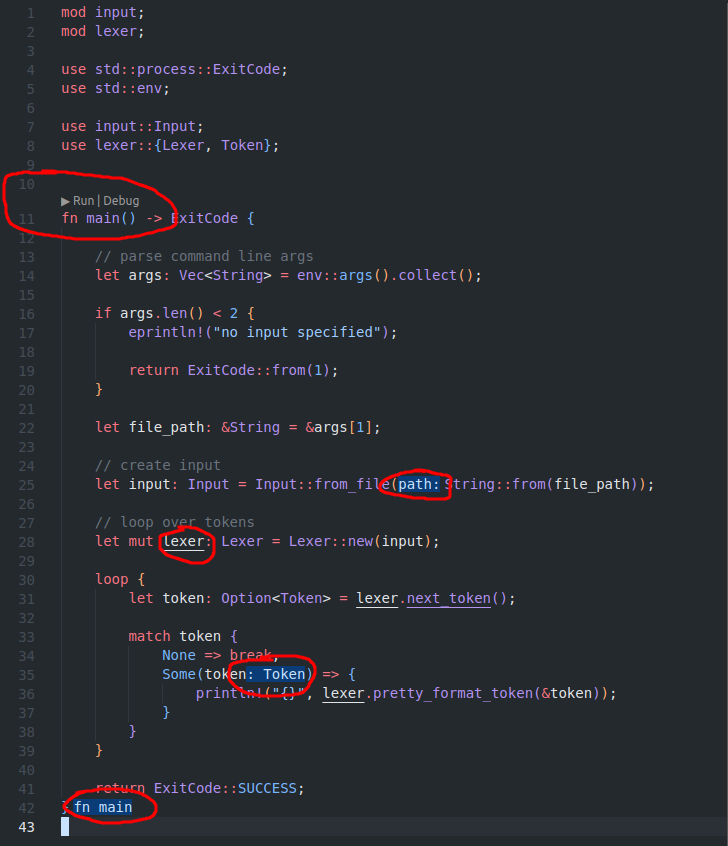
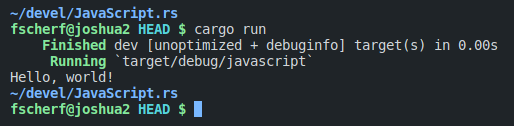
Since I am writing an interpreter, I need a way to point my code to the JavaScript file that should be used, read it character by character to lex it, do something with the tokens, and write something to the standard out. So I set up basic command line parsing, and wrote a function that takes a path to a file, read it, and iterate over its characters one-by-one.
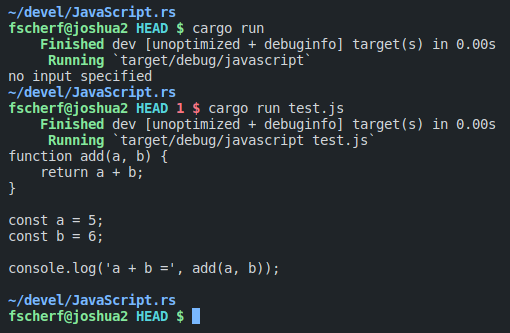
Great \o/ We implemented a shitty version of cat.
This seems like a very small victory, but to this point, I never had written a single line of Rust. I had read a lot of Rust code and Rust documentation, but, as always, that was like trying to learn to swim, on land.
The compiler was very unhappy with my first attempts and at some point I stopped entirely and went back to the Rust book, to reread some of the basic concepts. It was a tedious process, in particular since I knew what I wanted my program to do, and did it multiple times in other languages before, but Rust is very straightforward, and the compiler is very good at leading you in the right direction.
Implementing the Lexer
After this slow start, the development of the lexer went very smoothly and only took me two nights (I am surprised too). Rust has a very steep learning curve and feels very different from any other language I ever used before. After I overcame the initial hurdles and got used to the mental models on how to think about memory and ownership, Rust became very intuitive and fun to use.
I created some simple types for the lexer: An input, that holds the content of a JavaScript file and the information where the content came from, the lexer itself, which parses the given input and holds state on where the cursor currently is at, the token, and token-types. A token could be something like 10 and be of the token type TokenType::Int.
pub enum TokenType {
Name,
Function,
Return,
Const,
Dot,
Comma,
Semicolon,
Equal,
Plus,
SingleQuote,
RoundBraceOpen,
RoundBraceClose,
CurlyBraceOpen,
CurlyBraceClose,
String,
Int,
}
pub struct Input {
pub file: String,
pub content: String,
}
pub struct Token {
pub token_type: TokenType,
pub line: u32,
pub column: u32,
pub content: String,
}
pub struct Lexer {
pub input: Input,
pub cursor: u32,
pub line: u32,
pub column: u32,
}
The lexer gets initialized giving the "new" method the path of a JavaScript file. The lexer has a simple main loop that increments the cursor, and methods to parse the individual tokens. This is the method that parses string literals, for example:
fn parse_string(&mut self) -> Token {
let mut string_content: Vec = Vec::new();
let mut character: char;
let start_line: u32 = self.line;
let start_column: u32 = self.column;
self.increment_cursor();
loop {
character = self.get_character(self.cursor);
if self.is_quote(&character) {
break;
}
self.increment_cursor();
string_content.push(character);
}
self.increment_cursor();
Token {
token_type: TokenType::String,
line: start_line,
column: start_column,
content: String::from_iter(string_content.iter()),
}
}
After the lexer is done parsing, we can call lexer.next_token() and pretty-print the returned token until we reached the end of the input.
// create input
let input: Input = Input::from_file(String::from(file_path));
// loop over tokens
let mut lexer: Lexer = Lexer::new(input);
loop {
let token: Option = lexer.next_token();
match token {
None => break,
// print token
Some(token) => {
println!("{}", lexer.pretty_format_token(&token));
}
}
}
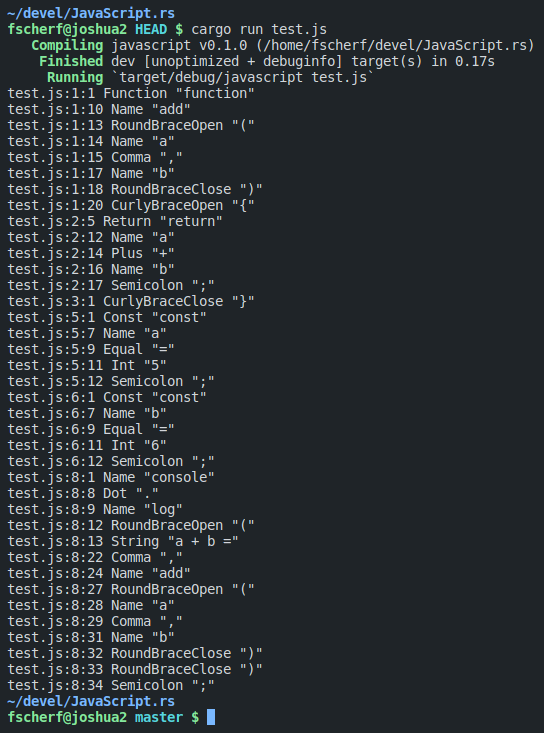
That's it! This was both harder, and easier than I thought initially. I thought it would be easier to get working with Rust, and harder to write the actual code for the lexer. I really liked the experience though. The more I learn about Rust, its concepts, its ecosystem, and its tooling, the more I like it.
The next step will be to write a parser, that converts the stream of tokens into an AST (abstract syntax tree). Stay tuned! :)